How I Setup Screaming Frog for SEO Crawls & Why
Essential Settings and Best Practices
Screaming Frog is one of the most powerful and widely used SEO tools for crawling sites. However, after training SEO Analysts and professionals on it since 2019, I’ve often noticed that new users struggle with the optimal settings for audits, and intermediate users struggle when they need to adjust configurations (most of the time for massive sites), and this leads to a sub-par crawl and missing key issues.
I will note, Screaming Frog is a BEAST of a tool for crawling sites, and this guide will walk you through my preferred Screaming Frog settings to maximize insights, improve crawl efficiency, and uncover critical SEO problems that might otherwise go unnoticed. However, if you’re looking for a comprehensive Screaming Frog tutorial – this blog is not that.
Storage Mode: Maximizing Efficiency and Data Integrity
Use Database Mode
By default, Screaming Frog runs in Memory (RAM) mode, which can limit performance and data retention. If you have an SSD (it’s 2025 so I sure hope you have an SSD), switch to Database mode for:
- Continuous auto-saving: Prevents data loss if Screaming Frog or your system crashes.
- Larger crawl capabilities: Enables crawling significantly larger websites without memory limitations.
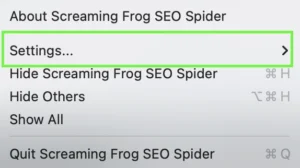
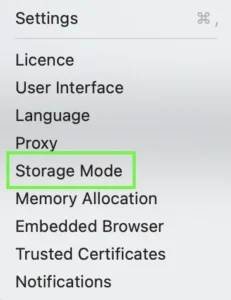
- Menu: Screaming Frog SEO Spider > Settings > Storage Mode > Database Mode
- Note: This is my preferred method, and why I provided screenshots above for you to locate it easier
Throughout this process, there will be lots of times you can click “OK” or “OK and Restart” – I set everything up at once, then click “Okay and Restart” when I’m done, otherwise I get annoyed at the multiple restarts.
Memory Allocation
Allocate as much RAM as you can towards crawling, but make sure you reserve at least 2GB for system stability. However, if you’re only leaving 2GB for system stability, just know you can’t do much else while the crawl is running. Most computers these days has at least 16GB of memory, so start with allocating 8GB.

Spider Settings: Spider > Crawl Config

Crawl Settings
Before we dive in, on each of these you’ll see a box for “Crawl” and “Store” – and this will be my quick definition for those:
- By default, the SEO Spider stores a lot of elements in your crawl database
- If “crawl” is checked, but “store” is not, screaming frog will still crawl those findings, but not store it in your crawl. Or think of it as the “noindex” tag, where you’re telling search engines you want the page crawled to discover links, but you don’t want the page itself in the index
- If “store” is selected but “crawl” is not, pages will be reported but not used for further discovery
The default settings for Screaming Frog does exclude certain elements that can impact the depth of the crawl. So I adjust these settings (Top Menu > Configuration > Crawl Config > Crawl):
✅ Crawl & Store for Pagination (Rel/Prev): This ensures you capture all paginated URLs, such as eCommerce product pages, and articles on large publisher sites.
✅ Crawl & Store Hreflang: Crucial for discovering alternate language versions and auditing multilingual SEO implementations.
✅ Crawl & No Check for Store AMP: While AMP (Accelerated Mobile Page) are becoming less common, I do come across these on more mature sites. This setting identifies AMP related issues, and ensures no hidden AMP pages are overlooked. It’s important to note, Google has moved away from AMP for their mobile first indexing, and now favors the broader “page experience” metrics such as load speeds and CWV (Core Web Vitals). Additionally, while both mobile friendly and AMP can lead to better mobile user experiences – studies show the majority of users prefer “mobile-friendly” over AMP pages. This is likely do to mobile phones having high-speed internet, and are more like mobile computers that can also be used as a communication device (telephone).

Crawl Behavior: How to Discover Hidden SEO Issues
By default, Screaming Frog does not crawl all subdomains or follow “nofollow” links. Modify these settings to uncover more insights:
✅ Crawl All Subdomains: This is essential for full audits, as subdomains can contain important SEO elements. Note, at a prior agency I had a very large enterprise level client, and their site had MASSIVE subdomains because their store, forums, videos, tutorials, etc., were all on subdomains. Luckily, the client on the other end, made me aware of all these so I could crawl them separately. There might be instances you keep this unchecked.
✅ Follow Internal nofollow: This helps you find onsite URLs marked with nofollow, and helps you analyze why they are used.
✅ Follow External nofollow: This will detect external broken links (404s), and allow you to update those. Remember, externally linking to a 404 is a bad user experience, and can be perceived as a negative ranking signal.

XML Sitemaps: Ensuring Complete Coverage
Screaming Frog does not auto-crawl XML sitemaps. Adjust these settings:
✅ Crawl Linked XML Sitemaps: Checks if all important pages are included and ensures there are no orphaned pages.
✅ Auto Discover XML Sitemaps via robots.txt: Saves time by automatically detecting sitemap locations.
✅ Crawl These Sitemaps: Ensures all known sitemaps are included in the audit. Sometimes you can get this from your client, GSC, etc. Just input the ones you know of because the keyword I used was “Sometimes you can…” and I’ve come across sites where there was no sitemap. The longer you’re in SEO, the more you’ll find certain fundamentals weren’t even followed by dev companies. I recently had a dev company tell me it was impossible to create a dynamic sitemap for SAP CC – which is categorically false.

Extraction Tab: Enabling Critical Insights

Page & URL Details
✅ Check HTTP Headers: This reveals hidden data such as dynamic content serving, caching issues, and security headers.
Structured Data
The default settings for structured data extraction is disabled. Enable these settings for full schema auditing:
✅ for each JSON-LD; Microdata; and RDFa: Extracts all schema markup regardless of implementation method. Keep in mind, JSON-LD is the official structured data format supported by Google, and it’s their recommended format.
✅ Schema.org Validation: This makes sure schema markup follows official guidelines.
✅ Google Rich Results Feature Validation: This validates against Google’s specific structured data requirements.
HTML
✅ Store HTML, and Store Rendered HTML: This is absolutely crucial for JavaScript-heavy sites to compare source code versus rendered content. Do you remember my Nespresso example in the SEO Audit Checklist?

Limits Settings: Expanding Redirect Tracking

⬆️ Increase “Max Redirects to Follow” from 5 to 20: This ensures complete tracking of redirect chains
Note: Limit Number of Query Strings: Sometimes I limit this to a handful, especially on sites where I know there are a lot of filtering options. However, it’s important to crawl these to ensure query string URLs are properly handled, such as a canonical to the non-query string URL.

Advanced Settings: Overriding Default Exclusions

By default, Screaming Frog ignores certain URLs and respects canonical directives, potentially missing valuable insights. This is why I adjust these settings:
❌ (Uncheck) “Ignore Non-Indexable URLs for On-Page Filters” This ensures non-indexable pages are still analyzed for SEO issues.
✅ “Always Follow Redirects” & “Always Follow Canonicals” – Helps uncover hidden or orphaned URLs.
✅ “Extract images from img srcset Attribute” – Ensures all images, including responsive ones, are analyzed.
Retain Visibility into All Pages
❌ By default, Screaming Frog respects noindex, canonicals, and pagination (rel/prev) directives. To see all URLs, leave these unchecked.

Duplicate Content Detection: Expand Coverage
❌ Uncheck “Only Check Indexable Pages for Duplicates” Even noindex pages may be duplicating content in ways that impact SEO.

Robots.txt Settings: Gaining Full Visibility
🛠 Set “Ignore robots.txt but report status” Helps identify mistakenly blocked URLs that may need reconsideration. If you leave the default “respect robots.txt” you likely won’t discover these URLs.


CDN Settings: Ensuring Image Audits
If a site uses an external CDN for images, add the CDN domain to Screaming Frog so it treats them as internal and audits them properly.
User-Agent Settings: Crawling Like Google
🕷️ Set User-Agent to Googlebot (Smartphone): Ensures you see what Google sees, detecting potential cloaking or mobile discrepancies.


*Important note, there are times sites / server settings block Screaming Frog from being able to crawl. Changing the User-Agent to a “Custom” setting, or “Screaming Frog SEO Spider” usually does the trick. If it does not, make sure you check the other settings to ensure you didn’t configure a really restrictive crawl accidentally. Also, I’ve come across plenty of sites that have had the robots.txt set to “Disallow: /” and/or every page of the site tagged “noindex” inadvertently. THIS IS WHY WE SETUP SCREAMING FROG ROBOTS AND NOINDEX IN THE WAY I DESCRIBED ABOVE SO YOU CAN AUDIT THESE THINGS.
API Access: Enriching Your Crawl Data
📊 Integrate Google Search Console & Google Analytics: Helps uncover orphan URLs and prioritize issues based on traffic data.
Final Step: Save Your Screaming Frog Configuration
Once all settings are optimized, go to File > Configuration > Save Current Configuration as Default. This ensures consistency for future crawls. Remember, you might have to tweak these settings for specific sites, and I do one of two things when that happens:
- I save the configuration for that specific site into the client folder, so I can load it quick
- If it’s just a couple of tweaks, I have a document with all my crawl, and SEO Audit notes on it, and I save what crawl settings I change in my default configuration for the site
Crawling & Auditing Sites for SEO Performance
Customizing your Screaming Frog settings is essential for conducting comprehensive SEO audits. By adjusting default settings to uncover hidden insights, you can:
- Identify orphaned pages, paginated URLs, and hreflang errors
- Detect structured data implementation mistakes
- Audit subdomains, redirects, and XML sitemaps effectively
By applying these settings, you ensure that no critical SEO issues go unnoticed. And as already mentioned, THESE SETTINGS ARE THE STARTING POINT FOR ME – THE MORE AND MORE MATURE A CLIENT’S SEO PROGRAM GETS, THE MORE THESE SETTINGS MAY CHANGE FOR THEM.
Helpful Resources for those New to SEO:
